Detect waste with Transformer
Transformers in the garbage detection service
 Transformer decoder is different from the originals. For N inputs, at the same time, it is able to decode N outputs in parallel.
Transformer decoder is different from the originals. For N inputs, at the same time, it is able to decode N outputs in parallel.In all our previous articles, we tried to detect waste from high- and low-quality images taken from many public datasets. For this purpose, we used Efficientdet, a popular state-of-the-art model for object detection. Our main goal was to localize garbage from photos taken in various environmental conditions. In this article, we will try something a little different to solve this task - DETR, which stands for DEtection TRansformer.
Transformer evolutions in computer vision
Detr is a set-based object detector using a Transformer on top of a convolutional backbone. Transformer decoder is different from the originals. For N inputs, at the same time, it is able to decode N outputs in parallel, instead of decoding one element at time.
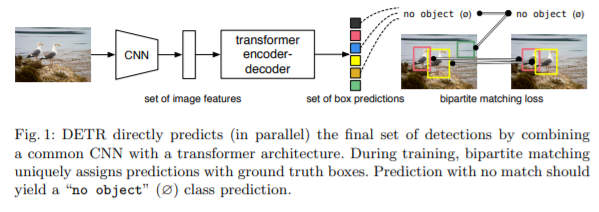
Architecture of DERT is overall very simple and easy to understand. Main components of DERT’s are backbone and Encoder-Decoder Transformer. The backbone is grounded on a conventional CNN structure which can generate a lower-resolution activation map - a feature map from the input image, which then is converted to a one-dimensional feature map, and passed into an Encoder-Decoder Transformer. Transformer encoder outputs are the N number of fixed-length embeddings, N stands for the maximum total number of instances that are assumed can be found by the model. Then this output is passed to a simple Feed-Forward Network (FFN). The network could predict bounding box and a particular class of object or class for ‘no object’.
In comparison to well-known two- or one-stage detectors, DETR does not need to set the number of anchor boxes (prototypical bounding boxes being candidate regions of detected objects), or even threshold for Non-Maximum Suppression (NMS) to filter out overlapping predicted bounding boxes.
Performance of DETR on TACO dataset
For our experiments we adapt the source code provided by the Facebook team to make everything work with our data. You can take a look at the detect-waste repository and play with the code. We started by analyzing the performance of DETR on a TACO dataset.
In our studies we took into account some prerequisites. Firstly, we chose the ResNet-50 backbone pre-trained on ImageNet. Taking a pre-trained backbone is a common practice since training from scratch is too long, and not effective enough. Second, since the dataset we are using is small, we loaded a pre-trained DETR model and finetuned it for detection of waste. The original DETR was trained on a COCO dataset which contains 80 classes plus background, but in case of TACO, there are 6 classes plus background: paper, glass, metal and plastic, bio, non-recyclable, and other. Therefore, the few last layers of the pre-trained DETR (classification head) have different weight shapes and are not used. After this we launch a training and check the first results.
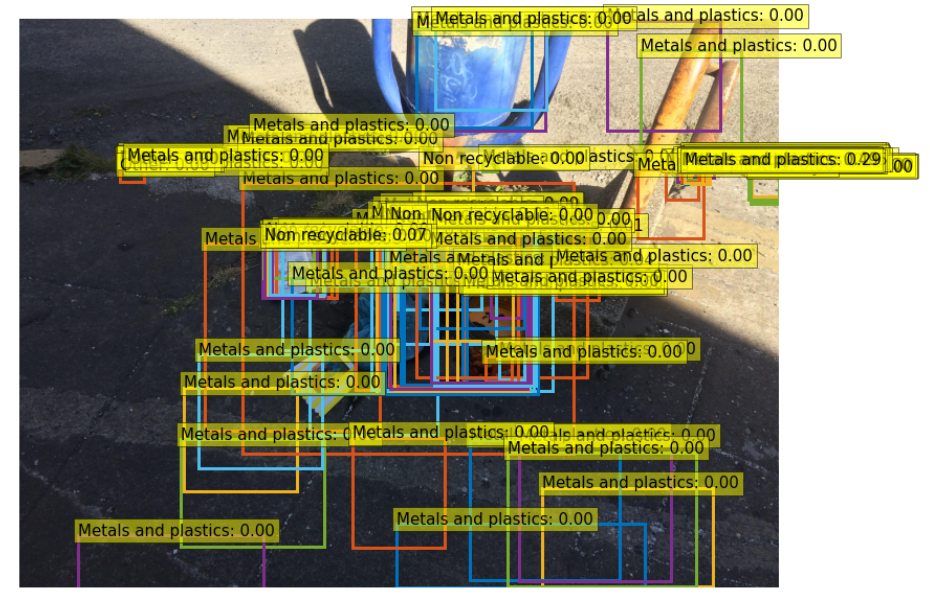
Unfortunately, in the beginning, our model did not really seem to get the idea of trash, which was mostly related to the small size of the dataset (only 1.5k images). Additionally, as was presented below, almost everything was treated as metal and plastic.
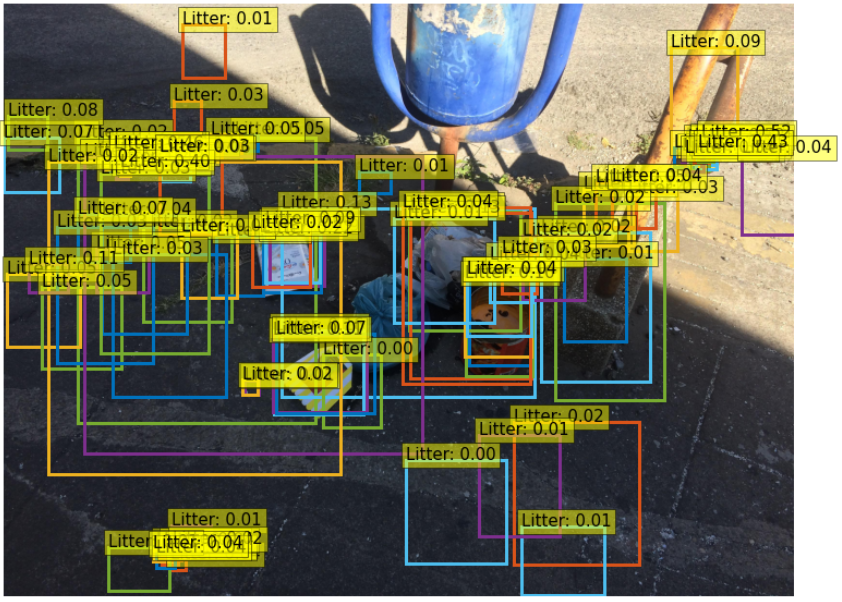
At this point we decided to simplify the task - teach model 2 classes: “litter” and “no object” (background). However, again the results were unsatisfactory.
The salvation for the model performance was the delivery of ~3k annotated images from our partner epinote.

Taking it to the streets
At this point we had not yet incorporated the images from other waste datasets. Also in the case of evaluation, we did not go beyond TACO, for example to test model performance on images scraped from google search. To prepare the model for this challenge, we trained it for 300 epochs, and with a learning rate beginning with 0.0001 with drop at 100th epoch. In this way, during our development, the model output started from this (6-class + “no object” DETR trained on TACO dataset):

finally ended with this (1-class + “no object” DETR trained on mixed dataset):

What can be easily seen, the performance of our model has increased significantly. This emphasizes the importance of big amounts of good quality data in artificial intelligence tasks. Analyzing the above images, we can see also some objects that the model did not localize. These are mainly small, distant instances, which in general are hard to recognize for detectors (especially for the origin version of DETR).
Simple comparison between Efficientdet and DETR
As mentioned in the introduction, in a previous articles we worked with Efficientdet detector. In our case Efficientdet fared better, both in terms of the quality of the predictions performed and the training time. On the other hand, the DETR’s pipeline can be easily extended to instance segmentation. But in the case of our mixed dataset this resulted mainly in the detection of grouped garbage - the model was losing the ability to identify individual instances. We suspect that this may be due to the annotation nature of some of the datasets used.

Overall, this article was a shallow introduction to waste detection with DETR. More about our work can be found in our github repo.
Sylwia Majchrowska
Deep Learning Researcher, PhD Candidate in Physics, STEM Teacher
PhD student in Physics at Wroclaw University of Science and Technology, and Deep Learning Researcher at NeuroSYS. She is a big fan of Python, eager to learn more about data science and machine learning.
Ewa Marczewska
Data Scientist in Hapag-Lloyd, Co-funder of WiML&DS Trojmiasto
Curious, inquisitive and passionate Data Wrangler. Experience in conceptual work as a philosopher and planner, with knowledge of solving multi-layers processes. Mainly work with data-driven visualizations and data storytelling. PhD thesis on using space syntax methodology in creating design for all environment. Responsible for cooperating in Women in Machine Learning & Data Science local chapter. Fluent in SQL, Tableau, R, Shiny, Python, Machine Learning.